Fault injecting on Ethernet
Ethernet runs so much of the modern world, and most of the time it works so well at the physical layer that the various layers of retransmissions and timeouts are rarely needed.
There is a huge range in the performance of networks, though, and small issues can amplify significantly if they are not handled correctly.
How confident would you be that an automated vehicle running safety-critical data over 1000BaseT1 Ethernet is going to be tolerant to data corruption? Perhaps caused by a damaged connector and excess vibration.
It is critical that we can test this type of scenario, and Quarch has the tools to do so. This month, we’ve been using our own tools to help track down a customer issue.
A real-life customer example
Our customer was running a Quarch PPM and developing a complex automation script to qualify storage devices. The issue was that the occasional command timed out and failed. This was weird, as the main power capture application was still running, and later commands worked fine.
We were unable to recreate the issue in our lab, but the customer helpfully shared a Wireshark trace (a capture of the network traffic).
Analysing this showed a major difference between our network and his. When capturing power data, our instrument streams data back to the PC over a TCP socket.
Wireshark has a handy tool to chart TCP streams, showing the data rate and packet sizes going past. First, we see the performance of our network:
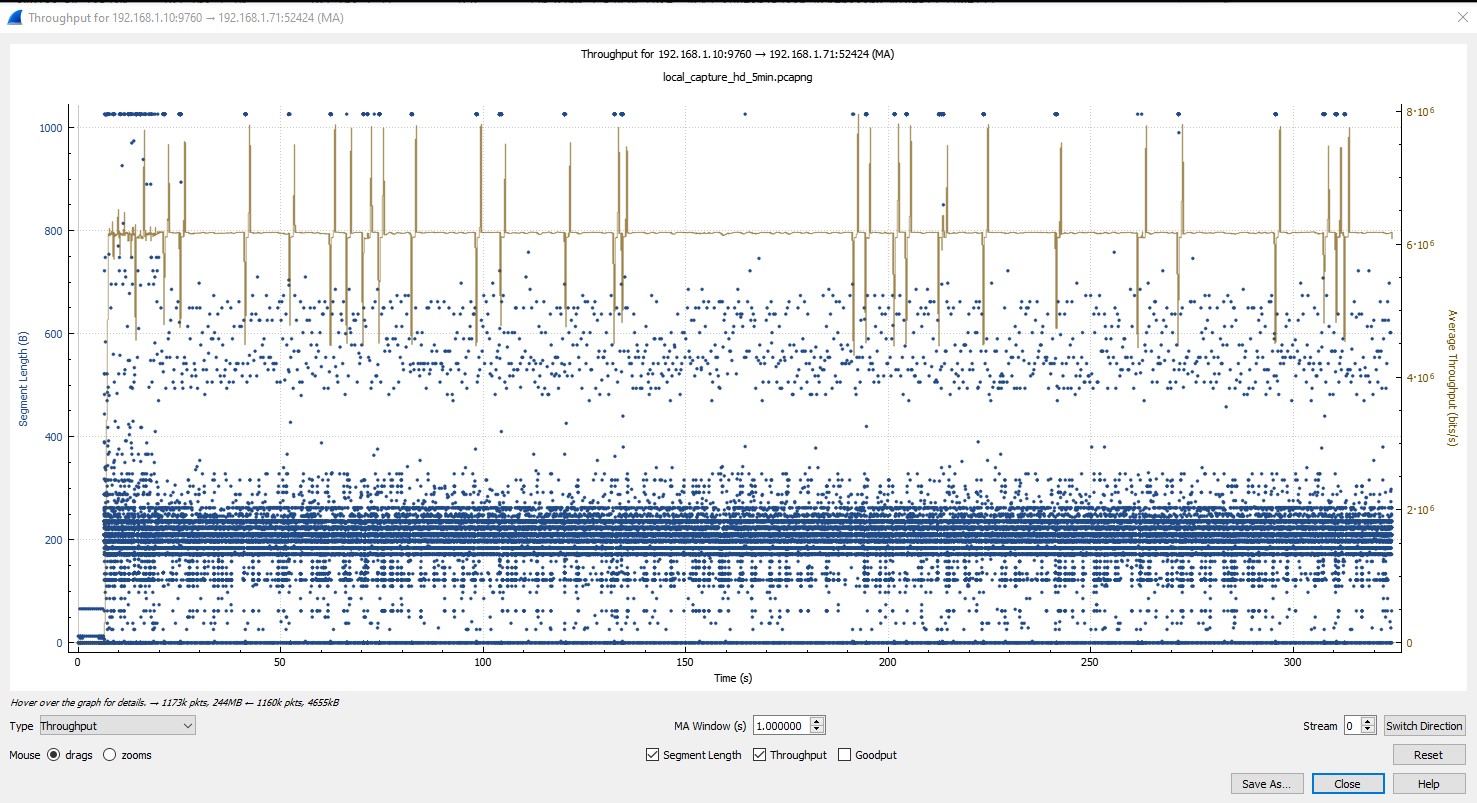
The customer network looks very different, the data rate is all over the place, and there are gaps of 1-2 seconds where no data is sent at all.

We also saw TCP ‘retransmissions’ on the customer network, where a packet has been corrupted or otherwise dropped by the network and then has to be sent again. This is unusual but a known issue on a LAN that should be handled easily.
Recreating the issue
So now we could see that something unusual was going on and that our product was not acting as expected, but we did not know what the specific issue was. It’s much easier to debug something when you can repeat the failure in your own lab with access to all the development tools. It also avoids hassling the customer to keep ‘trying things’ to give you more information.
Fortunately, Quarch is good at breaking networks. I grabbed a QTL2022 – RJ-45 Cable Breaker, a physical layer fault injection tool that can disconnect or glitch a network link.

Of course, I didn’t end up making a nice photogenic test setup, but it was a working one!

With this, I could inject a physical layer error into the LAN link, disrupting the passing data. I didn’t need scripted automation, just simple faults, so I used Testmonkey to control the QTL2022.
Using the ‘Signal Glitching’ option, I started with a single 10mS glitch on all pairs while I had the PPM running. This immediately terminated the test, as the network link went down.
A couple more experiments, and I found that a 1uS glitch was short enough to avoid the Ethernet link going down but would be plenty long to disrupt a packet if the glitch fell in the middle of one.
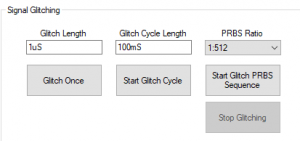 Next, I had to actually hit a packet. I used the PRBS (Pseudo Random Bit Sequence) generator to create a random series of glitches across the link. A 1 in 512 ratio is equal to 0.19% of the total time on the link being disconnected on average.
Next, I had to actually hit a packet. I used the PRBS (Pseudo Random Bit Sequence) generator to create a random series of glitches across the link. A 1 in 512 ratio is equal to 0.19% of the total time on the link being disconnected on average.
Successful recreation of the customer issue
With this running, I got a successful recreation of the customer issue. I saw the occasional command time out and also saw disruption in the TCP throughput
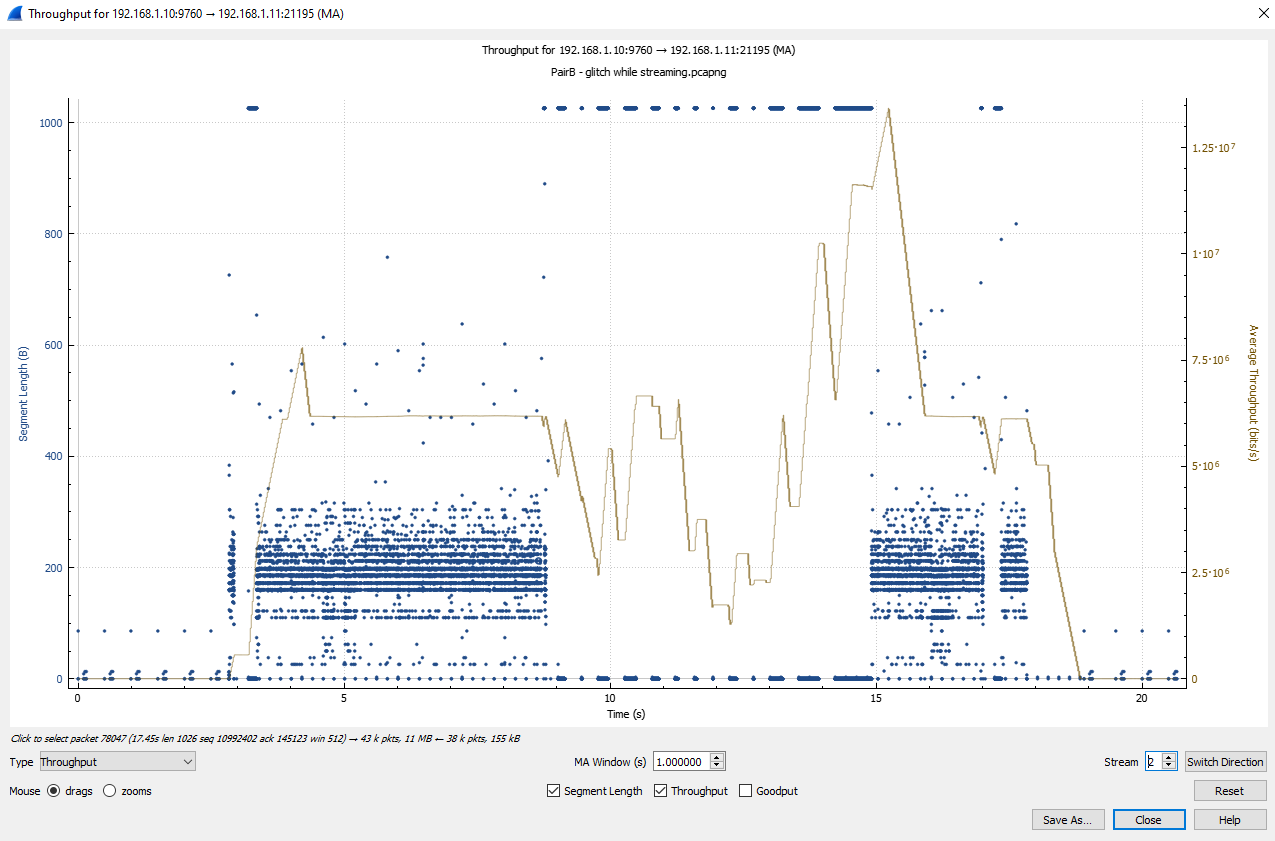
We don’t see exactly the same as the customer, but I created the same fault scenario. This quickly allowed us to debug and find two issues
- An incorrectly set command timeout at 1 second, when it should have matched the much longer TCP timeout.
- The HD network stack was using a 1-second retransmission timeout. Rather than adapting to the average round-trip time of the link, as is standard (meaning we were halting for longer than required),
Both of these issues were quickly patched, and the customer was back up and running.
Conclusions
- It’s incredibly useful to have a way to recreate issues locally. Having the right test kit for a problem can vastly reduce the time taken to solve it
- Modern networks are ‘normally’ very robust, but unusual cases must be accounted for. Packets can be lost at any time, and complex ripples of timeouts can occur
In this case, a sub 0.2% physical interruption on the bus lead to around a 40% loss in practical throughput. Increasing the interruption to 1.5% dropped the throughput by 90%.
In cases where network integrity becomes safety-critical, a designer must be able to prove that a physical link interruption can be handled.

Andy Norrie